Auteurs : Mario Bensi, Ludovic Dupont, Kévin Ottens, Sébastien Taupiac
D'une manière générale, le scheduleur applique la politique d'ordonnancement choisie pour le système. En clair, le scheduleur gère la séquence des processus élus.
Dans le cas de Linux, cette opération d'ordonnancement se passe en trois temps :
La fonction schedule() est appelée principalement dans trois cas :
La première étape de l'ordonnancement est la mise à jour de l'état du processus courant. Cette actualisation est effectué par le code suivant :
asmlinkage void schedule(void)
{
struct schedule_data * sched_data;
struct task_struct *prev, *next, *p;
int this_cpu, c;
/* [...] */
if (prev->policy == SCHED_RR)
goto move_rr_last;
move_rr_back:
switch (prev->state & ~TASK_EXCLUSIVE) {
case TASK_INTERRUPTIBLE:
if (signal_pending(prev)) {
prev->state = TASK_RUNNING;
break;
}
default:
del_from_runqueue(prev);
case TASK_RUNNING:
}
prev->need_resched = 0;
repeat_schedule:
/* [...] */
move_rr_last:
if (!prev->counter) {
prev->counter = NICE_TO_TICKS(prev->nice);
move_last_runqueue(prev);
}
goto move_rr_back;
/* [...] */
}
Si le processus est temps réel et a une politique de «Round Robin», on commence par le placer en fin de liste, et réinitialiser son compteur (goto move_rr_last). Ensuite, on change son état selon trois cas :
Elles entrent en jeu dans la seconde partie de l'ordonnancement : la sélection du processus à élire. La variable next est un pointeur sur le processus élu. c est le critère de sélection du processus.
Ces deux variables sont initialisées de la manière suivante :
La liste des processus éligibles est ensuite parcourue afin de sélectionner celui qui possède le poids le plus fort. En effet, pour chaque processus le scheduleur appelle la fonction goodness() :
static inline int goodness (struct task_struct * p,
int this_cpu, struct mm_struct *this_mm)
{
int weight;
if (p->policy != SCHED_OTHER) {
weight = 1000 + p->rt_priority;
goto out;
}
weight = p->counter;
if (!weight)
goto out;
/* .. and a slight advantage to the current MM */
if (p->mm == this_mm || !p->mm)
weight += 1;
weight += 20 - p->nice;
out:
return weight;
}
Elle retourne une valeur (appelée poids ou weight) qui est calculée en fonction de sa priorité (p->nice) et de sa tranche de temps restante (p->counter). Une fois le parcours de la liste terminé, c contient le poids le plus important et next pointe sur le processus auquel correspond ce poids.
Il existe plusieurs cas remarquables pour la valeur de c :
L'étiquette «recalculate» est atteinte lorsque tous les processus ont consommé leur tranche de temps. Autrement dit, c contient la valeur 0. Il convient alors de ré attribuer des tranches de temps à tous les processus prêts.
asmlinkage void schedule(void)
{
struct schedule_data * sched_data;
struct task_struct *prev, *next, *p;
int this_cpu, c;
/* [...] */
if (!c)
goto recalculate;
/* [...] */
recalculate:
{
struct task_struct *p;
spin_unlock_irq(&runqueue_lock);
read_lock(&tasklist_lock);
for_each_task(p)
p->counter = (p->counter >> 1) + NICE_TO_TICKS(p->nice);
read_unlock(&tasklist_lock);
spin_lock_irq(&runqueue_lock);
}
goto repeat_schedule;
/* [...] */
}
Ce calcul est basé sur la valeur de la tranche de temps et sur la priorité. Il peut paraître étrange de faire ce calcul en fonction de p->counter. En effet, comme c=0 tous les p->counter devraient être nuls. Or cela n'est pas forcément le cas, des interruptions ont pu faire apparaître de nouveaux processus (dont le p->counter est non nul).
Tout d'abord, voici le code prenant en charge la commutation de processus :
asmlinkage void schedule(void)
{
struct schedule_data * sched_data;
struct task_struct *prev, *next, *p;
int this_cpu, c;
/* [...] */
if (prev==next)
goto same_process;
kstat.context_swtch++;
switch_to(prev, next, prev);
same_process:
return;
/* [...] */
}
Le déroulement de la commutation de processus est assez simple. Tout d'abord, si le processus élu reste le même le scheduleur ne fais rien. Sinon, on garde trace de la commutation dans kstat (structure de statistique du noyau, voir linux/kernel_stat.h pour plus de détails), puis on effectue la commutation à proprement parler. Une fois cette dernière vérification effectuée, le scheduleur a terminé sa tâche et s'arrête.
D'un point de vue global, le noyau Linux applique une politique d'ordonnancement avec réquisition utilisant une priorité variable. Toutefois on distinguera deux types de politique d'ordonnancement plus spécifiques pour les processus : processus temps réel, processus «classiques».
La première chose remarquable dans le cas d'un processus temps réel provient de la fonction goodness(). En effet, ce type de processus a un poids fixe, qui dépend seulement de sa priorité temps réel (p->rt_priority), et qui est très supérieur au maximum des poids des processus classiques. Ainsi, un processus temps réel est toujours choisi en premier ce qui garantit un temps de réponse très court pour ce type de processus. Dès qu'un processus temps réel a besoin du microprocesseur, il est sûr de l'obtenir au prochain it_timer.
Il faudra noter deux «sous-classes» des processus temps réel : les processus ayant une politique de «Round Robin» et les processus ayant une politique «FIFO».
Le cas des processus classique est différent, leur poids est variable. Il dépend de leur priorité (p->nice) et de la valeur de la tranche de temps restante (p->counter).
De cette manière, le processus est soumis à un «vieillissement» : plus il utilise le processeur, moins il a de chance d'être élu. Ainsi on garantit que tous les processus utiliseront le processeur tout en conservant un meilleur temps de réponse pour les processus très prioritaires.
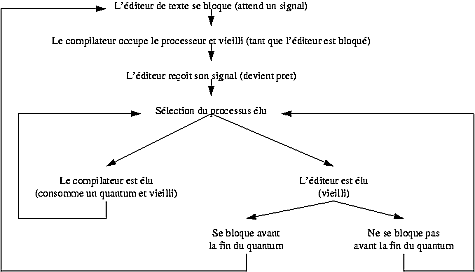
Considérons le scénario suivant : deux processus, un éditeur de texte et un compilateur, sont actifs. Le premier est fortement interactif, le second ne l'est pas du tout. Voici un petit diagramme qui résume le déroulement de l'ordonnancement :
Comme on peut le voir sur ce schéma, le processeur ne reste jamais sans rien faire car on tire partie des blocages. De plus, même si le compilateur a une priorité très élevée par rapport à l'éditeur de texte, ce dernier fini par prendre la main puisque le compilateur va «vieillir» plus vite.
Pour conclure, il parait intéressant de faire le bilan des avantages et des inconvénients de l'ordonnancement du noyau Linux.
Le principal inconvénient vient de la prise en compte des processus temps réel. Il est nécessaire d'utiliser des programmes temps réel «honnêtes» c'est à dire des processus qui tiennent compte de l'avantage qui leur est offert. En effet, un programme temps réel malintentionné peut facilement monopoliser les ressources de la machine et provoquer une famine.
En revanche, si on écarte le cas des processus temps réel, cette politique offre des avantages non négligeables. Premièrement le risque de famine est inexistant, chaque processus ce verra élu dans des délais acceptables grâce au principe de vieillissement. Et deuxièmement, comme l'ordonnancement se fait aussi au changement d'état du processus courant, on tire partie des blocages d'un processus pour éviter les temps morts. Le processeur est utilisé de manière optimale.